This is part of a series of posts explaining cryptic tech terms in an introductory way.
Disclaimer: this series is not intended to be a main learning source. However, there might be follow up posts with hands-on experiments or deeper technical content for some of these topics.
Motivation
Let's start by proposing a problem. Assume you have a system consisting of a serving node that simply takes a request from a client and routes it to the correct back-end node after altering some aspects of that request.
First thing you notice that serving node can be a bottleneck if not scaled proportionately to the traffic hitting it. We'll probably need a multi-node serving system. How can we route requests to a cluster of nodes?
Take a moment here and think of potential solutions before scrolling.
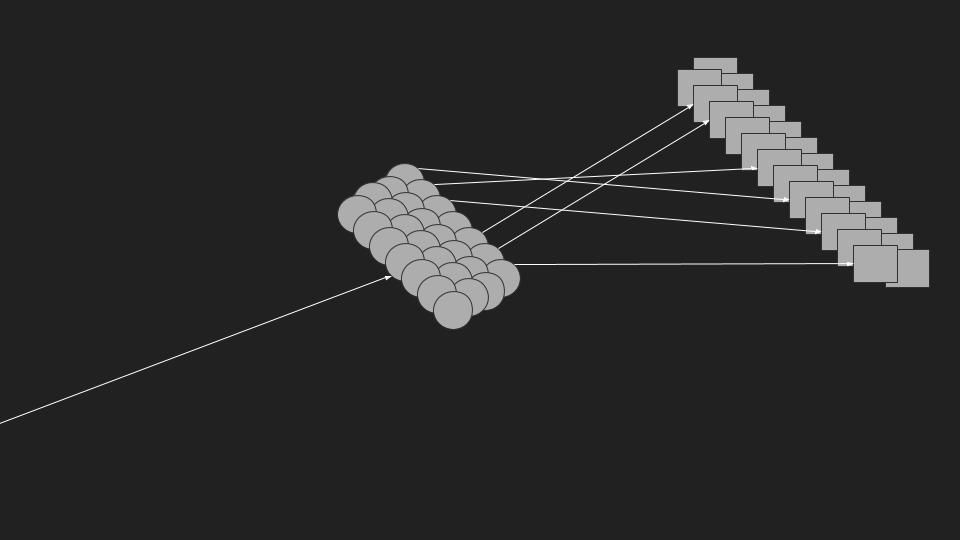
Use all the load balancers!

Well, maybe. Load balancing is a very good technique to scale up systems. But let's take a deeper look at what that load balancer would look like. Would the load balancer be a single node serving a multi-node system? It seems like load-balancing might be the answer but we'll need more than just a single node load balancing.
Client-based load balancing
That's a good idea. Clients are by nature scaled up to the traffic (they are the traffic). Let's make the client aware of all the serving nodes and let it decide which node to talk to based on some semantics of the client. Let's create a smart client that can hash a request and get a serving node.
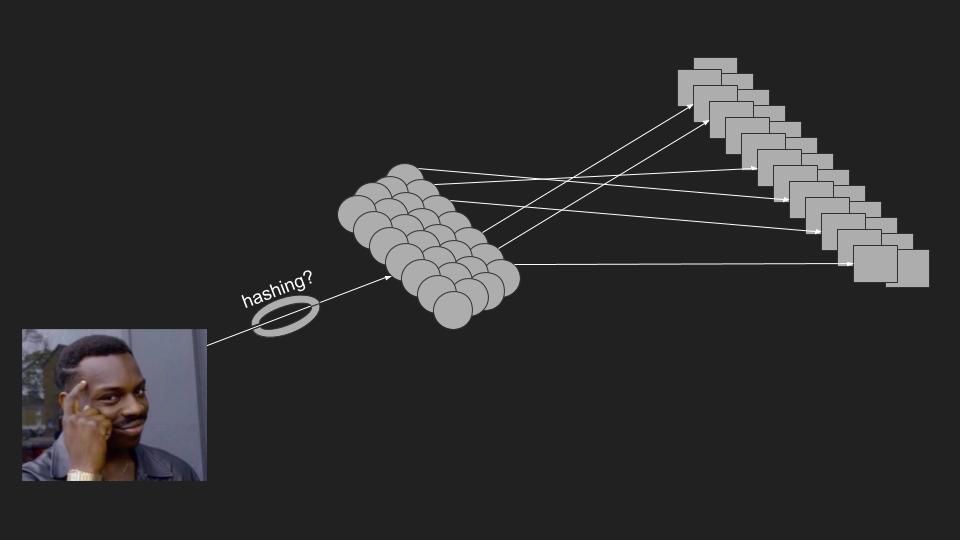
That's great. We have a client that can know which node to call directly depending on that client's identity. Assuming uniform load between all clients, this should be a good solution.
But what if the client-assigned serving node crashed?
Take a moment here and think of potential solutions before scrolling.
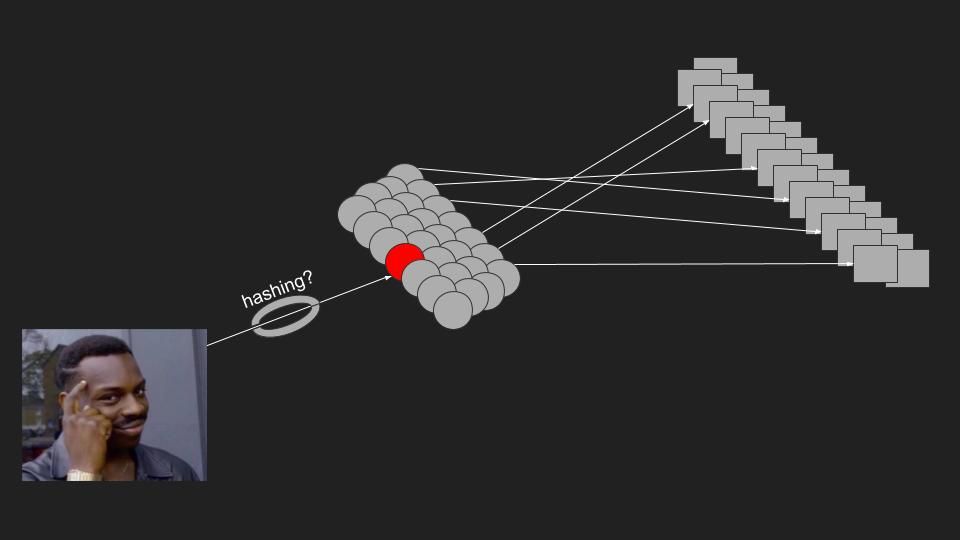
Can we do better?
In traditional hashing you give a one-way method input X (client-id in our example) and it returns H(X) result (serving node address in our example). This is a widely used concept and part of almost all programming languages in a way or another. The shortcoming of that in our example happens when H(X) points to a failing node. This is problematic because the client doesn't know any extra information to fall back to. This is where rendezvous hashing shines. Instead of hashing single input single output, rendezvous hashing takes the form H(Sn, X) = Cn
Where Sn is set of elements (serving nodes in our example), X is the input for hashing (client-id in our example) and returns Cn an ordering of Sn weighted with a complete scoring (think of it as confidence values adding to 1).
Take a moment here and think how this form can be useful in our example.
Using rendezvous hashing gives us a node we should talk to (the top of the list Cn) but it also gives us an ordering for fail-over if the node failed. This is very interesting because it didn't only solve the load balancing fail-over issue but it also established whats called distributed k-agreement. Imagine a write request coming to the nodes, this write need to be replicated across nodes in some way so if the node that received the write request failed, the client can fail over to the next. In our scenario, if the client and serving nodes share the same H(Sn, X), nodes can decide the order of replication and create a replication chain that follow the same order as how the client would fallback. Assume we have a discovery service that basically just keeps track of all the nodes around, all members can distributively adapt to changes in the nodes structure without having to communicate with the other nodes.